Batch Analytics
Overview
Process big data jobs in seconds with Azure Data Lake Analytics. There is no infrastructure to worry about because there are no servers, virtual machines, or clusters to wait for, manage, or tune. Instantly scale the processing power, measured in Azure Data Lake Analytics Units (AU), from one to thousands for each job. You only pay for the processing that you use per job.
U-SQL is a simple, expressive, and extensible language that allows you to write code once and have it automatically parallelized for the scale you need. Process petabytes of data for diverse workload categories such as querying, ETL, analytics, machine learning, machine translation, image processing, and sentiment analysis by leveraging existing libraries written in .NET languages, R, or Python.
In this lab Learn how to
- use Data Lake Analytics to run big data analysis jobs that scale to massive data sets
- how to create and manage batch, real-time, and interactive analytics jobs, and
- how to query using the U-SQL language
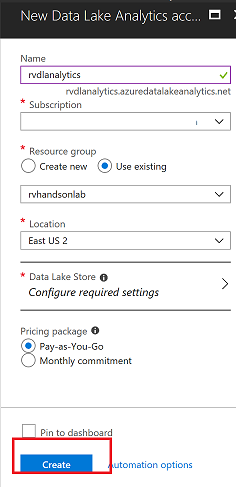
Task 1: Create Azure Data Lake Analytics Service
Create Data Lakae Analytics service to mine data stored in Data Lake Store.
Click on Create a resource

Click on Data + Analytics

Click on Data Lake Analytics

Pick the Data Lake Store where device telemetry data is being stored from Stream Analytics job
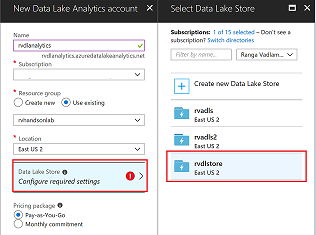
Use existing resource group and click on Create button
Task 2: Create Sample Data and Install Extensions
Click on Sample scripts
Click on sample data missing button to create sample data in Data lake Store
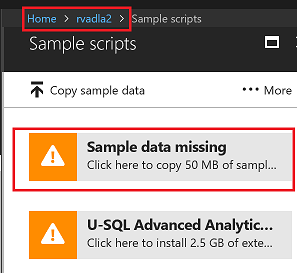
You should see successful message after data is copied
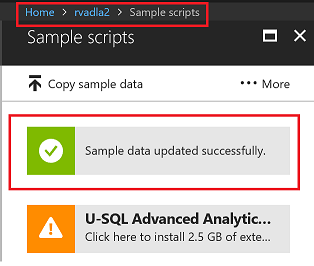
Install Extensions
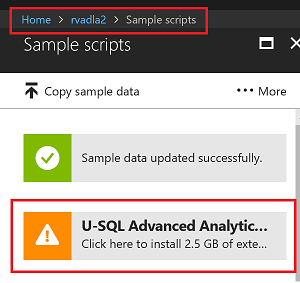
Successful Extension installation
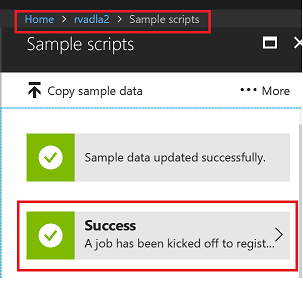
Task 3: VS Code Integration
Submit Job using VS Code, Try Samples First to Learn through Data Lake Analytics
Install VS Code Extension for Data Lake Analytics
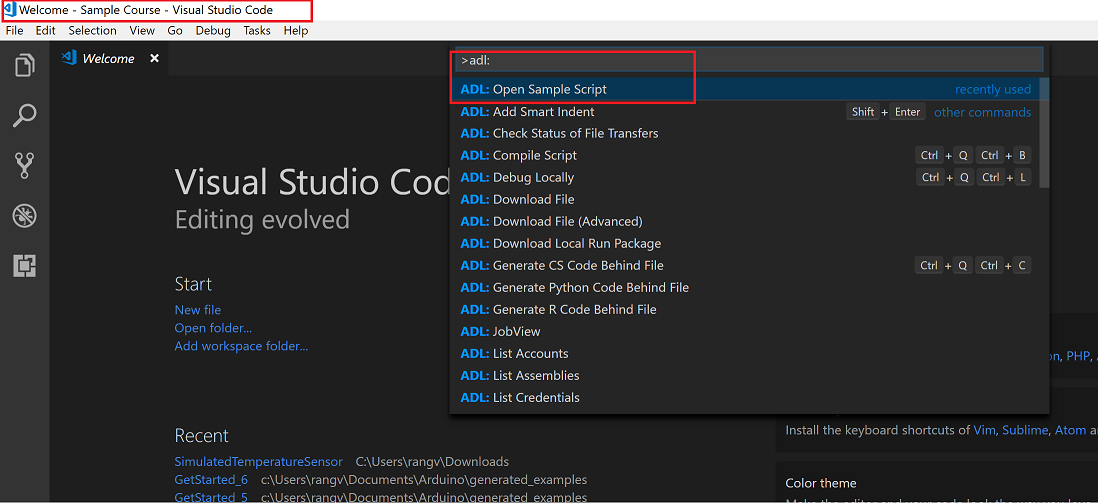
Run Samples
Run Samples to learn Data Lake Analytics
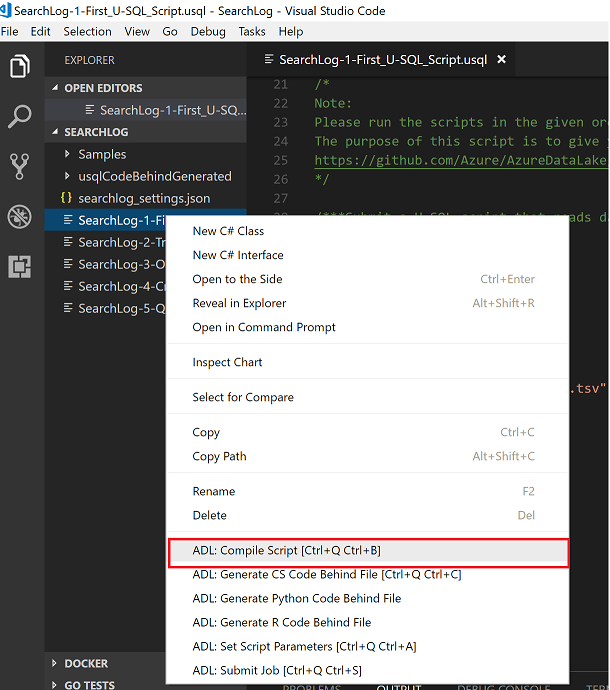
Compile Script
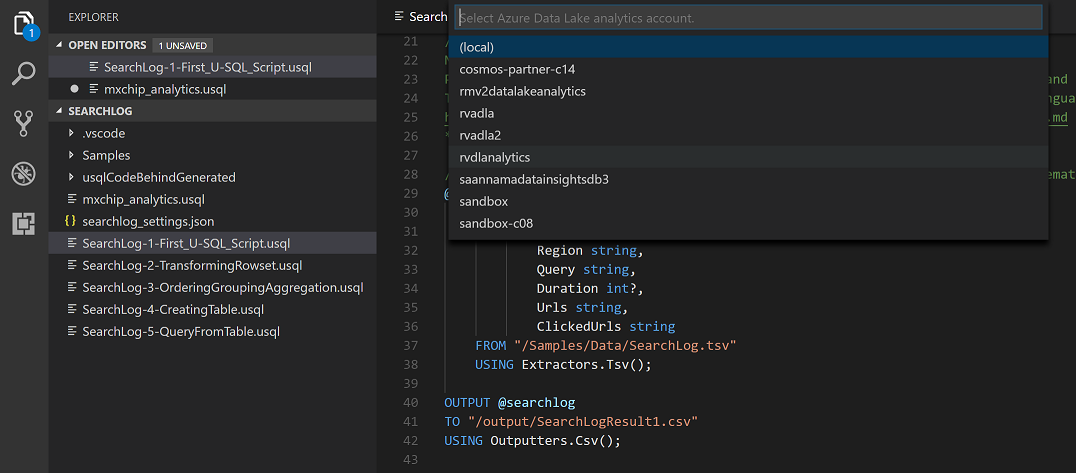
Click on List more accounts
![Run Samples]./media/11_VSCode_Open_Sample_Script_Compile_Select_Account.png)
Select a Data Lake Analytics Account
Select master key
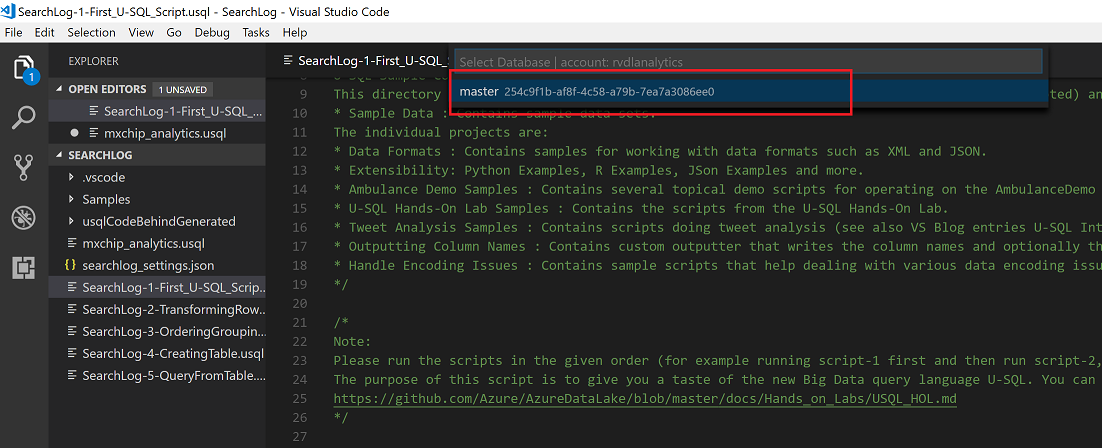
Compile as USQL
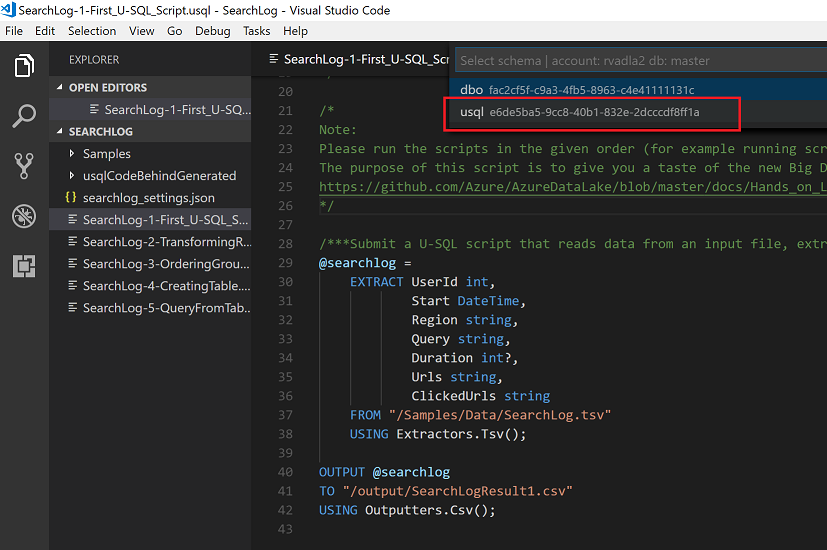
USQL script should be compiled
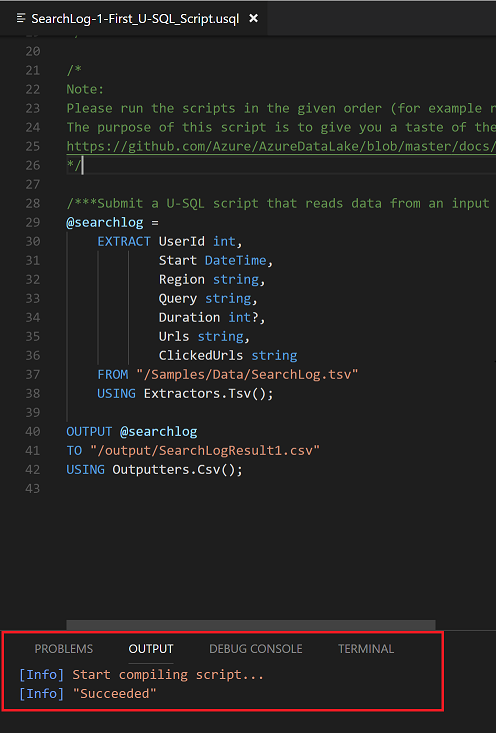
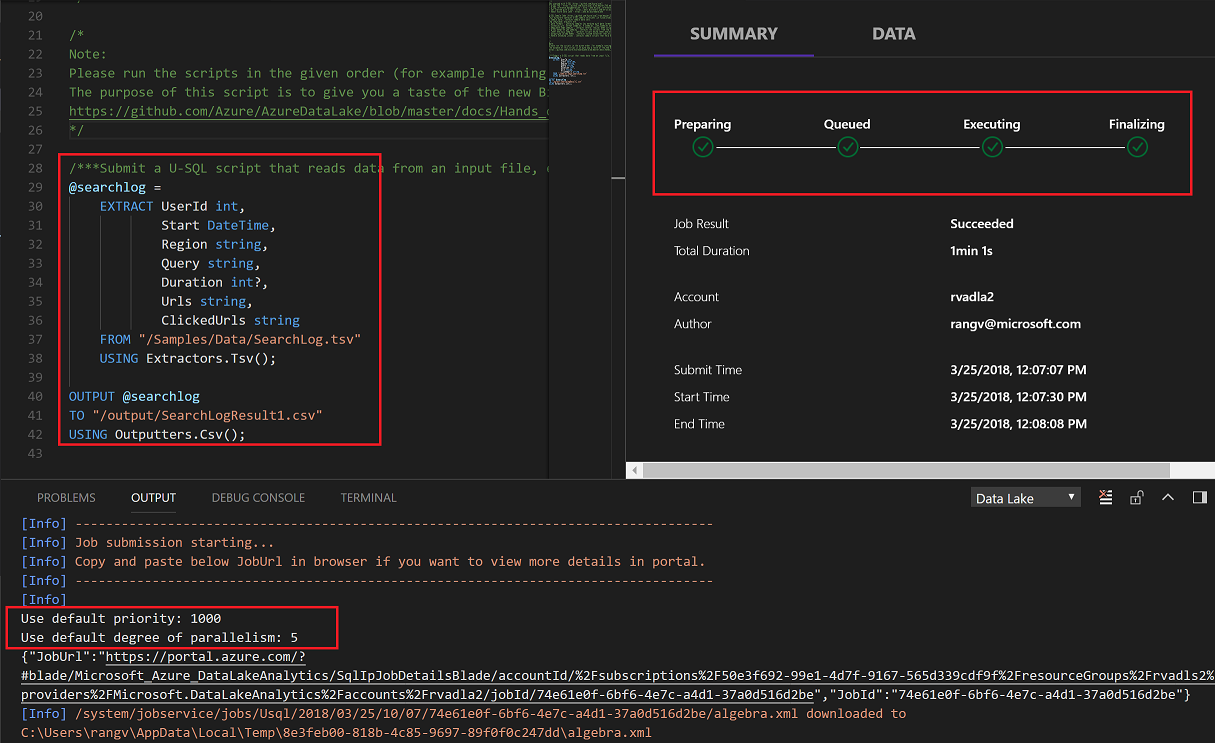
Submit Job To Run
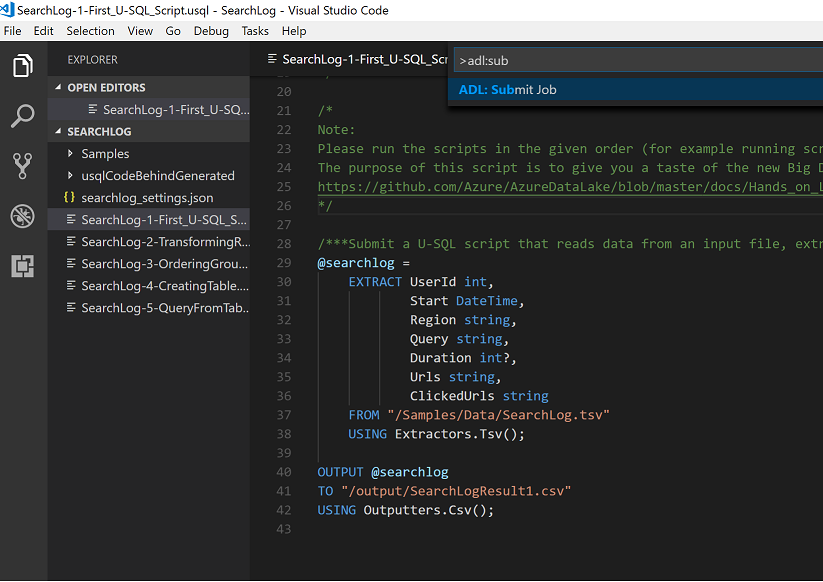
Default priority is 1000 and number default number of nodes to run the script are 5
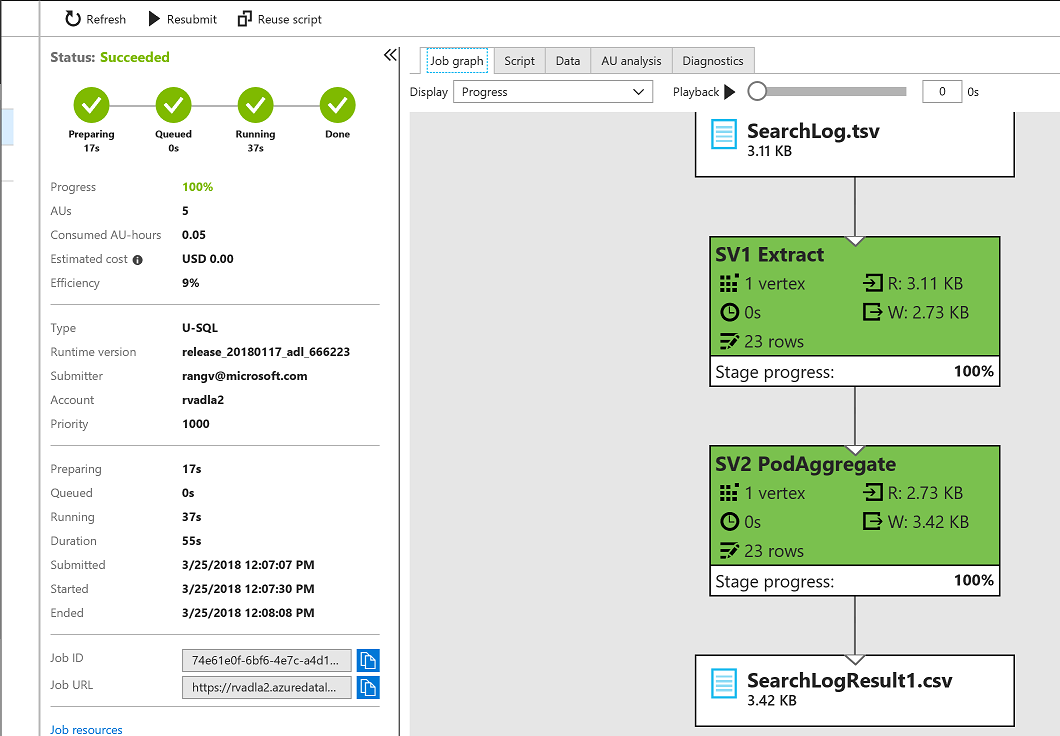
Job Success with Job Analytics
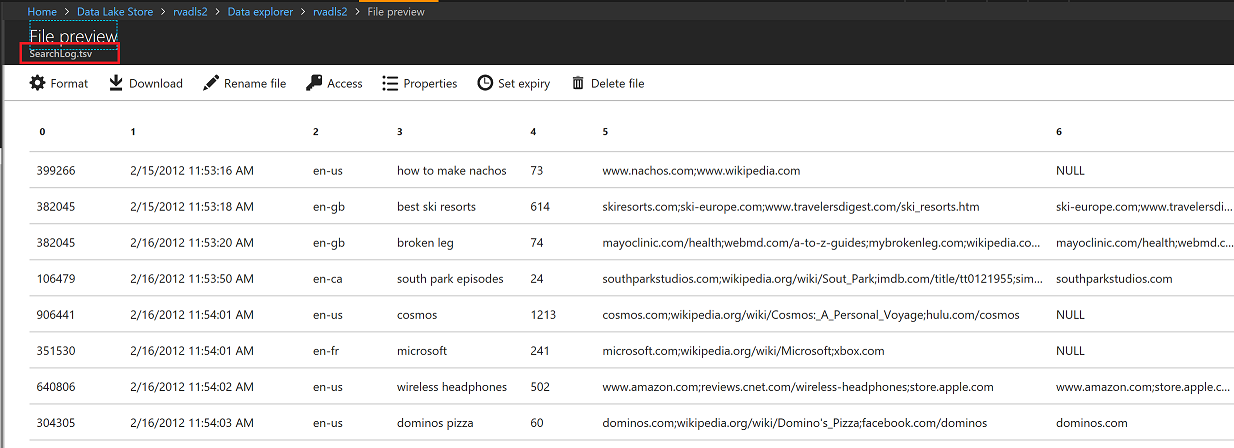
View Input File
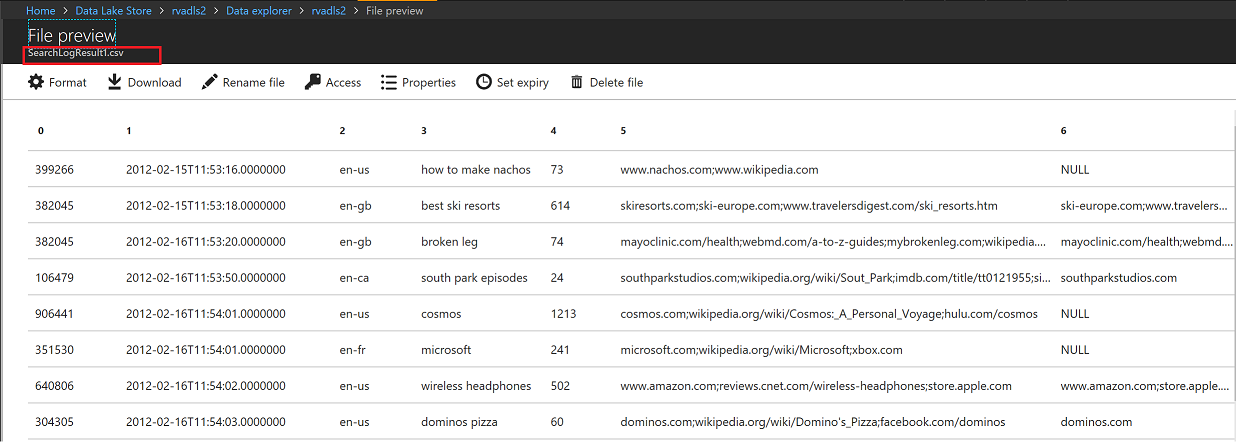
View Output File
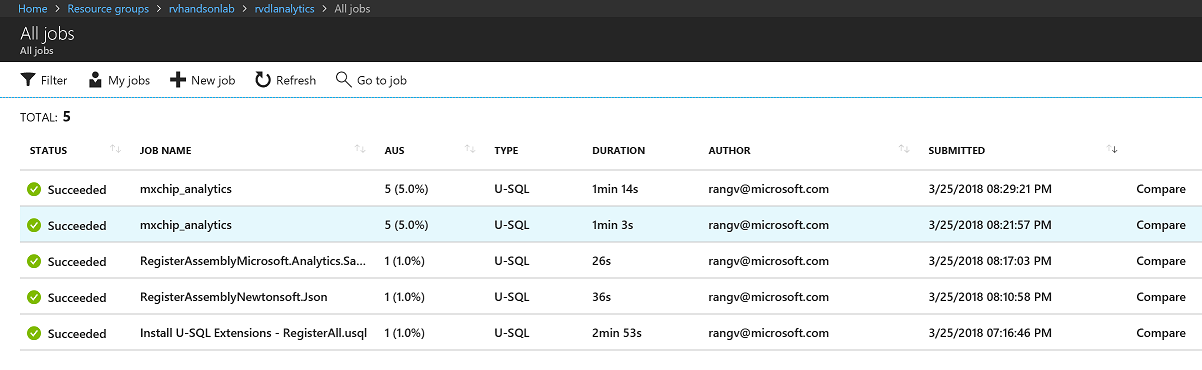
Task 4: Create an Analytics Job against MXChip (or Simulator)
Create an analytics job to convert JSON to CSV using U-SQL and Data Lake Analytics
Create a new mxchip_analytics.usql file in the project
REFERENCE ASSEMBLY [Newtonsoft.Json];
REFERENCE ASSEMBLY [Microsoft.Analytics.Samples.Formats];
//Extract the Json string using a default Text extractor.
@json =
EXTRACT jsonString string FROM @"/workshop/streaming/2018/03/{*}/{*}.json" USING Extractors.Tsv(quoting:false);
//Use the JsonTuple function to get the Json Token of the string so it can be parsed later with Json .NET functions
@jsonify = SELECT Microsoft.Analytics.Samples.Formats.Json.JsonFunctions.JsonTuple(jsonString) AS rec FROM @json;
@columnized = SELECT
rec["deviceId"] AS deviceId,
rec["temperature"] AS temperature,
rec["humidity"] AS humidity,
rec["time"] AS time
FROM @jsonify;
//Output the file to a tool of your choice.
OUTPUT @columnized
TO @"/workshop/output/out.csv"
USING Outputters.Csv();
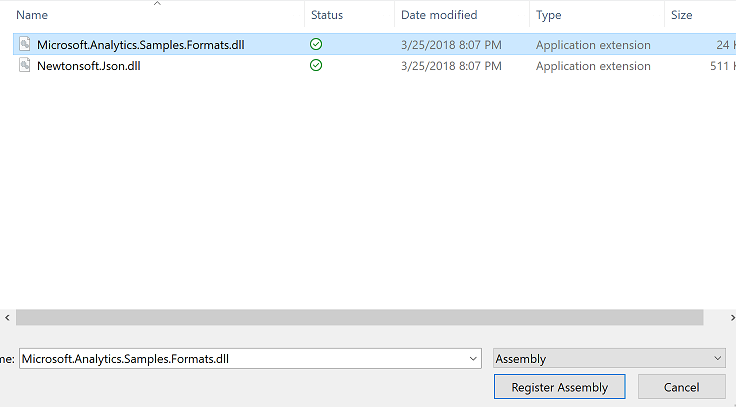
Register two assemblies Newtonsoft and Samples.formats. Download the dlls from /libs folder and register
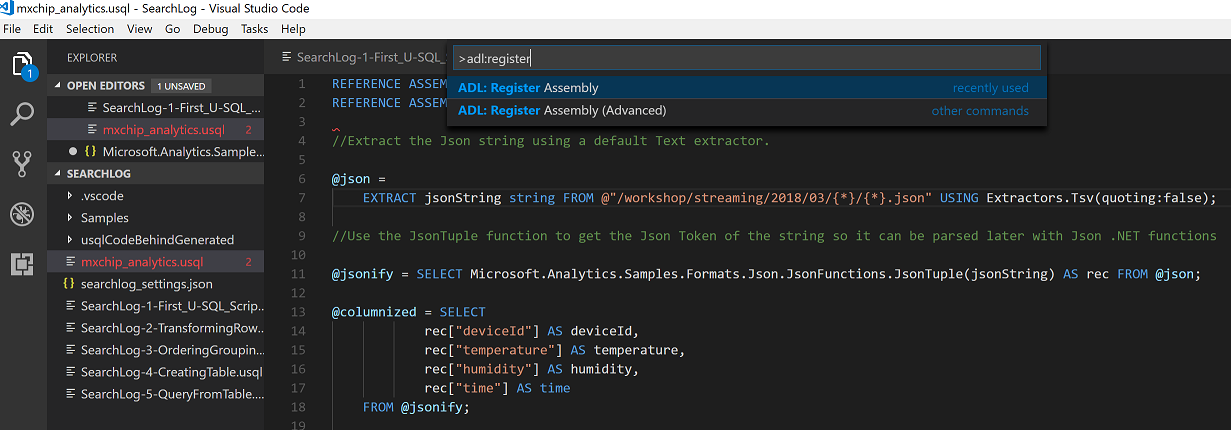
Select the dlls from the /libs folder
Submit Job
Submit Job to convert all JSON files to CSV files
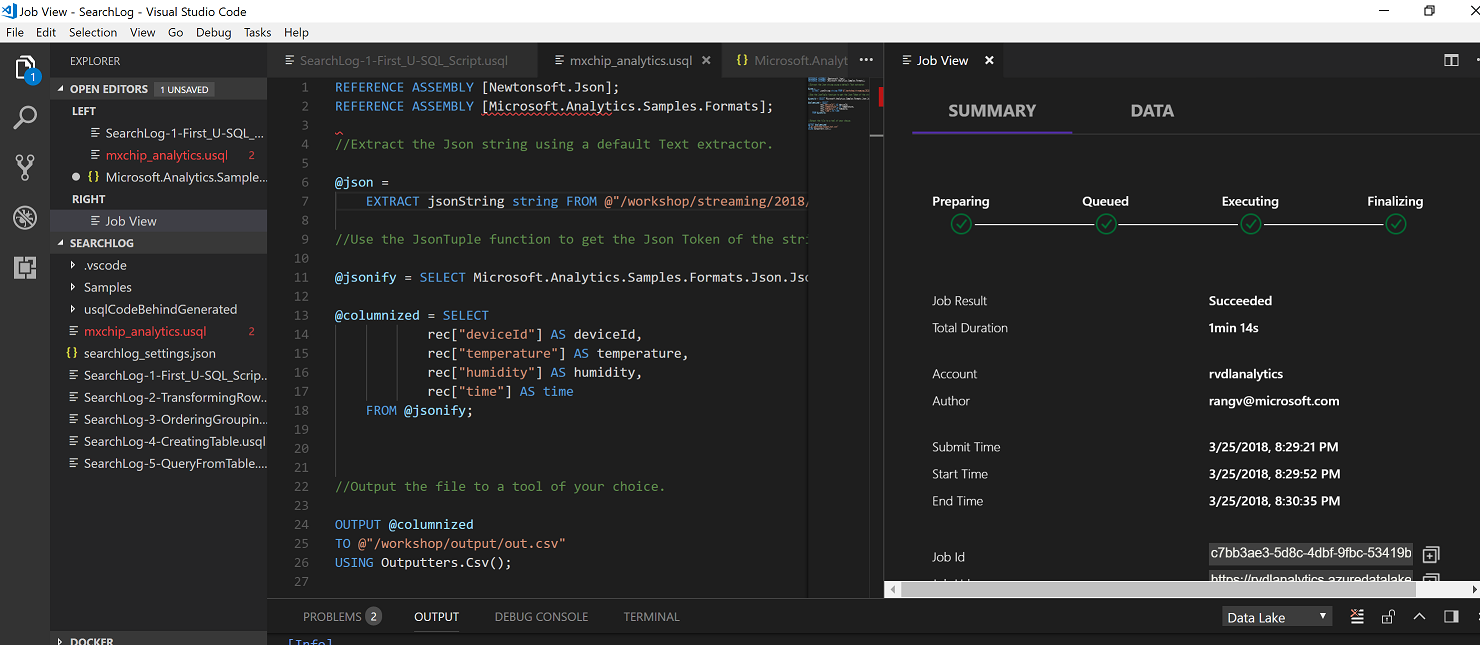
View Jobs